Ollama for Solo Consultants: 5 Honest Wins From a Local Setup

Ollama runs my local LLM stack on M-series Mac. Five wins from a solo consultant’s first month — and the workflow it quietly broke.
Ollama runs my local LLM stack on M-series Mac. Five wins from a solo consultant’s first month — and the workflow it quietly broke.

Obsidian’s AI plugins reshaped my knowledge base this month. Five patterns from a solo consultant’s vault, with one I dropped after a week.
Parameter Golf gave AI agents a 16MB sandbox. Five lessons it leaks about real AI-assisted research workflows for solo consultants.
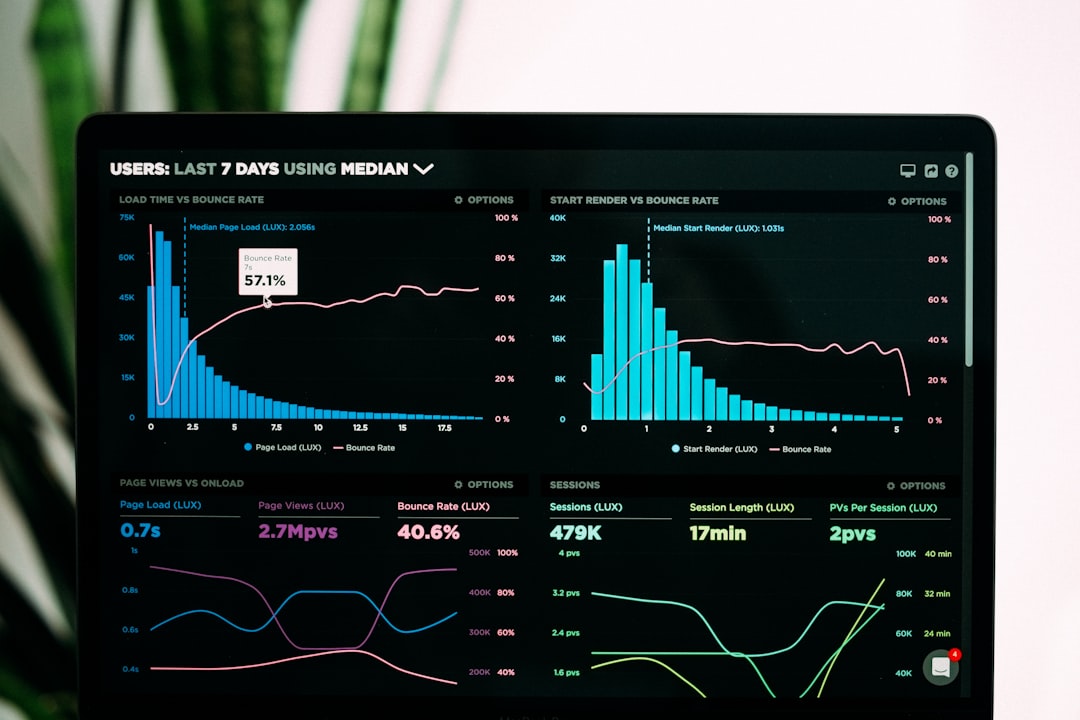
NVIDIA gave 10,000 employees Codex access this month. Here is what the rollout reveals about a solo consultant’s coding stack.

After eight months alongside Claude and ChatGPT, the five recurring slots where Gemini still earns weekly time in a solo freelance stack.

One million tokens. What DeepSeek V4 context actually unlocks for solo consultants — and where it stays off the table.

Solo writer, 18 months on Jasper’s Creator plan. The honest answer on whether $39/mo earns its slot when Claude Pro is half the price.

After OpenAI’s privacy refresh, I rewrote how I handle client drafts in ChatGPT. Four small settings, real differences.

OpenAI confirmed ad testing in ChatGPT this month. Here’s what it means for a freelance week built around the app.

A Korea-based solo operator’s guide to subscribing, paying, and expensing US AI tools — with the VAT trap that costs you 10% if you skip it.

Solo consultant doing 6+ pitch prep cycles a month. The exact ROI math on whether Perplexity Pro pays for itself versus the free tier and Google.

GPT-5.5 Instant is now ChatGPT’s default model. Here are the three changes that actually affect how freelancers use it: shorter outputs, fewer hallucinations, and a memory panel you can audit.