Cursor Composer 2.5: 4 Honest Signals From a Non-Developer Week
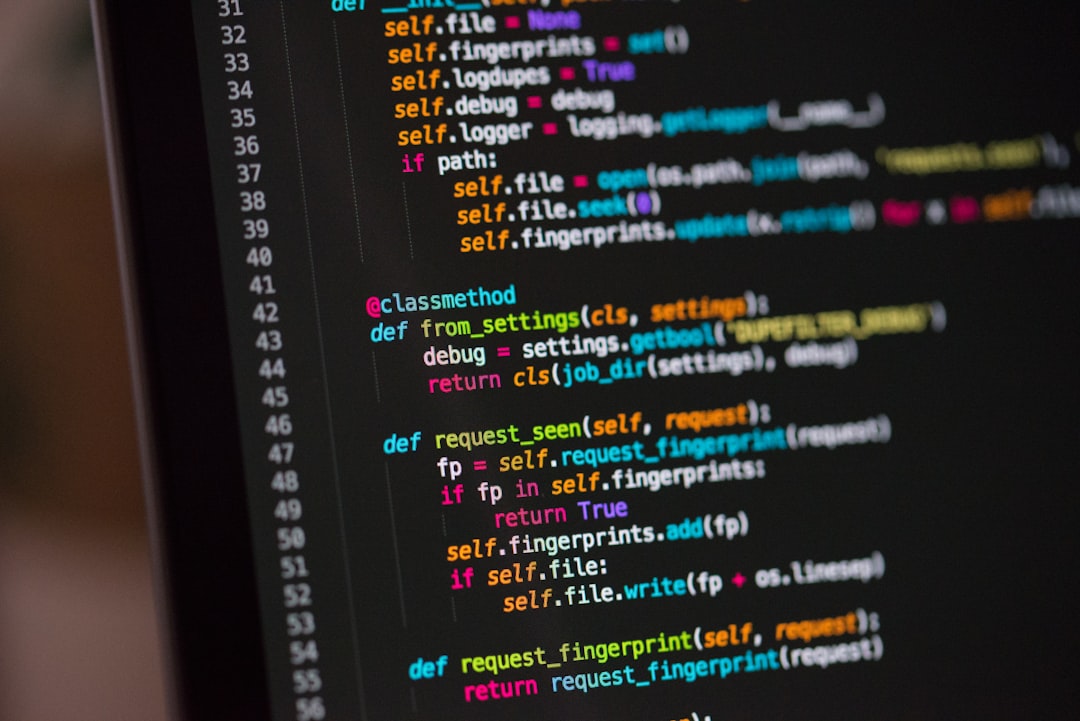
Cursor’s new Composer model claims smarter long-running tasks. Four signals from a non-developer’s CSV cleanup week.
Cursor’s new Composer model claims smarter long-running tasks. Four signals from a non-developer’s CSV cleanup week.

Notion turned the workspace into a hub for AI agents this month. Four shifts a solo consultant feels in a daily stack.

Claude Sonnet 4.6 became the default on claude.ai this month. Four shifts a solo consultant feels in a daily AI stack.

After OpenAI’s privacy refresh, I rewrote how I handle client drafts in ChatGPT. Four small settings, real differences.

OpenAI confirmed ad testing in ChatGPT this month. Here’s what it means for a freelance week built around the app.

GPT-5.5 Instant is now ChatGPT’s default model. Here are the three changes that actually affect how freelancers use it: shorter outputs, fewer hallucinations, and a memory panel you can audit.

OpenAI’s April 2026 post-mortem reveals how GPT-5 personality training can drift undetected—and what solo consultants should do about it.

Two $100 AI tiers, one decision. The five real differences I’d weigh before swapping my Plus and Pro stack.

A news brief from a solo operator’s seat — what the April 27 partnership rewrite actually changes for the people paying $20–$200 a month, not the boardroom. In this post TL;DR What the OpenAI Microsoft deal actually changed First-party products stay on Azure 3 things that actually move for a freelance stack What does NOT … Read more

Content mode: Informed — Field Report. I haven’t personally tested GPT-5.5 against Claude Code yet — this is what the public benchmarks and pricing pages say before I commit to a paid month of side-by-side use. I haven’t used this yet, but here’s what the data shows. OpenAI released GPT-5.5 yesterday (April 23, 2026), and … Read more